软件项目随着业务发展,一个单体的应用的问题会暴露出来,各个开发人员开发不同的功能模块,造成代码冲突,单体应用上线必须所有功能一起上线,风险较大。这时项目必然需要被拆分,拆分为一个个独立的应用服务,拆分后会导致系统服务间调用链路愈发复杂。
此时,一个前端请求可能最终需要调用多个后端服务才能完成实现,当整个请求不可用出现问题时,我们是没有办法判断请求是由哪个后端服务引发问题,这时我们需要快速定位故障点,找到调用异常的服务,跟进一个请求到底有哪些服务参与,参与顺序是怎样,从而达到每个请求的步骤清晰可见。于是就有了分布式系统调用跟踪的需求。
目前,链路追踪组件有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
这些开源组件都是基于Google的Dapper。 Google在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
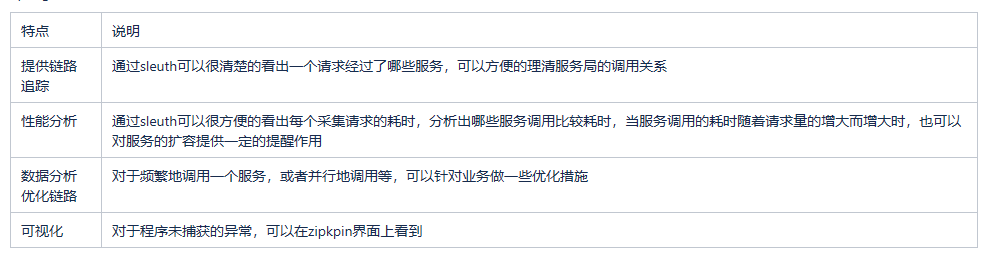
Spring Cloud Sleuth有4个特点
对于开发者来说,如果想要封装其他的框架,就需要对跟踪的数据模型有一个清晰的认识:
Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,就是每个方法调用的id。
Trace :一组代表一次用户请求所包含的spans,其中根span只有一个。
Annotation:包括一个值,时间戳,主机名。用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
cs - Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
一般情况下,分布式服务跟踪系统,主要包括有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。

服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
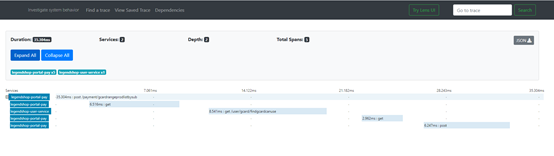
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。

使用官方镜像地址:
https://hub.docker.com/r/openzipkin/zipkin